
Org-Bench: Let’s Simulate the Org Charts Meme with Agents and See Who Wins
And prepare to have your mind blown.

You might have seen Manu Cornet’s org charts picture at some point. It became a popular meme because the stereotypes felt so accurate.
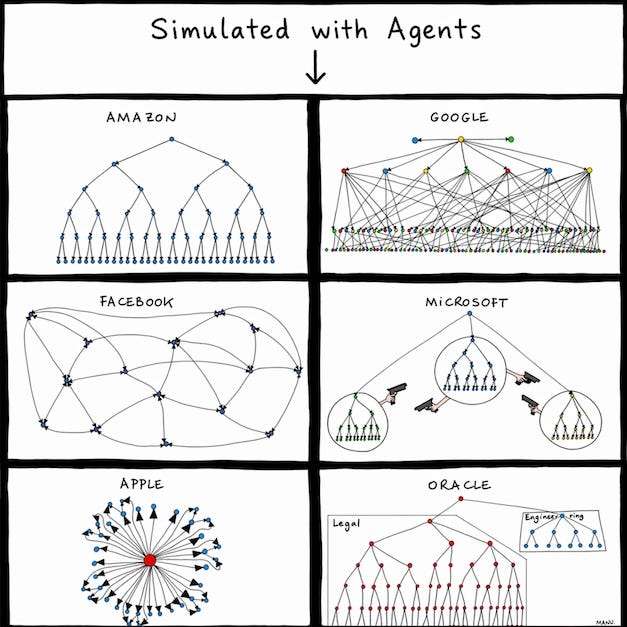
But have you ever wondered how these org structures would actually perform, if we put them to work and compare results side by side?
I say it’s time to get some data! We have agents now - let’s reproduce these org charts with agent teams and see how they work. Same input, same model, six org archetypes wired up as multi-agent topologies, each one asked to ship the same product.
Who will ship the best product in the shortest time? Let’s find out!
Spoiler alert: I ended up spending hundreds of millions of tokens and these agent teams took days to run. The result really blew my mind. I can’t wait to share that with you.
Setup
Here’s the benchmark setup I designed for running the simulation. Everything from the benchmark harness to the result datasets are all open sourced at https://github.com/kunchenguid/org-bench.
The task: Build an in-browser spreadsheet in vanilla HTML/CSS/JS. The project brief is in configs/brief.md.
The agent harness: We use opencode which is a CLI agent harness. The biggest thing I like about opencode is that it’s model-provider agnostic, which allows us to easily test different models down the road.
One agent = one opencode session. Every agent is a separate opencode session running in its own subprocess. Every agent and the judge all run on openai/gpt-5.4. Any output difference between topologies comes from topology, since the agent harness and models are all consistent.
Per-run isolation. Every run gets a disposable sandbox. At the end of each topology run the whole directory gets wiped, so two topology runs never see each other’s work.
Topology config. A topology is a plain TypeScript object: an array of agent names, a list of bidirectional edges (who can message whom), a named leader, a list of developers, a list of integrators (the agents allowed to merge PRs to main), and a culture definition string. The six configs all live in configs/topologies/.
Inter-agent communication. Messages route through per-agent inboxes. The orchestrator enforces adjacency: If an agent tries to send to someone they don’t have an edge with, the message gets dropped. This is the whole “org structure” machinery - the edge list enforces the org structure.
A round. Every agent wakes every round. Within a round all agents execute in parallel (each opencode session gets one prompt, runs tools, writes a JSON reply); the round only ends when the last one finishes or a safety timer fires. Rounds are sequential - round N+1 doesn’t start until round N is complete. We cap at a total of 28 rounds to avoid infinite rabbit holes.
Per-round prompt. Each agent’s prompt is assembled by the orchestrator from:
How many rounds remain
The agent’s persona - leader vs developer vs integrator
The team charter (everyone’s expectations, not just yours, so agents can infer what peers are working on)
The agent’s direct neighbors and their roles
The culture summary for that topology
The path to the brief
The agent’s current inbox messages
The agent-browser CLI reference
A required reply format: JSON with a
messages: [{to, tag?, content}]array and an optionalsummary
Git flow. Developers commit to their own per-agent branch, push, open a PR targeting run/<run-id>/main (or a staging branch under a sub-lead for Amazon/Oracle). Only integrators (defined per topology) can merge PRs; everyone else’s merge attempts bounce.
Finalize. When the leader emits THIS_IS_MY_FINAL_SUBMISSION, the orchestrator considers the work done and sends the judge a single prompt asking it to drive the result app through agent-browser like a user and return an 8-axis rubric JSON. We report the average score across the rubric.
The orchestrator is otherwise hands-off. No human in the loop, no scoring intervention, no retries of failed PRs.
The results
Without further ado, drumroll please... the final results are here!
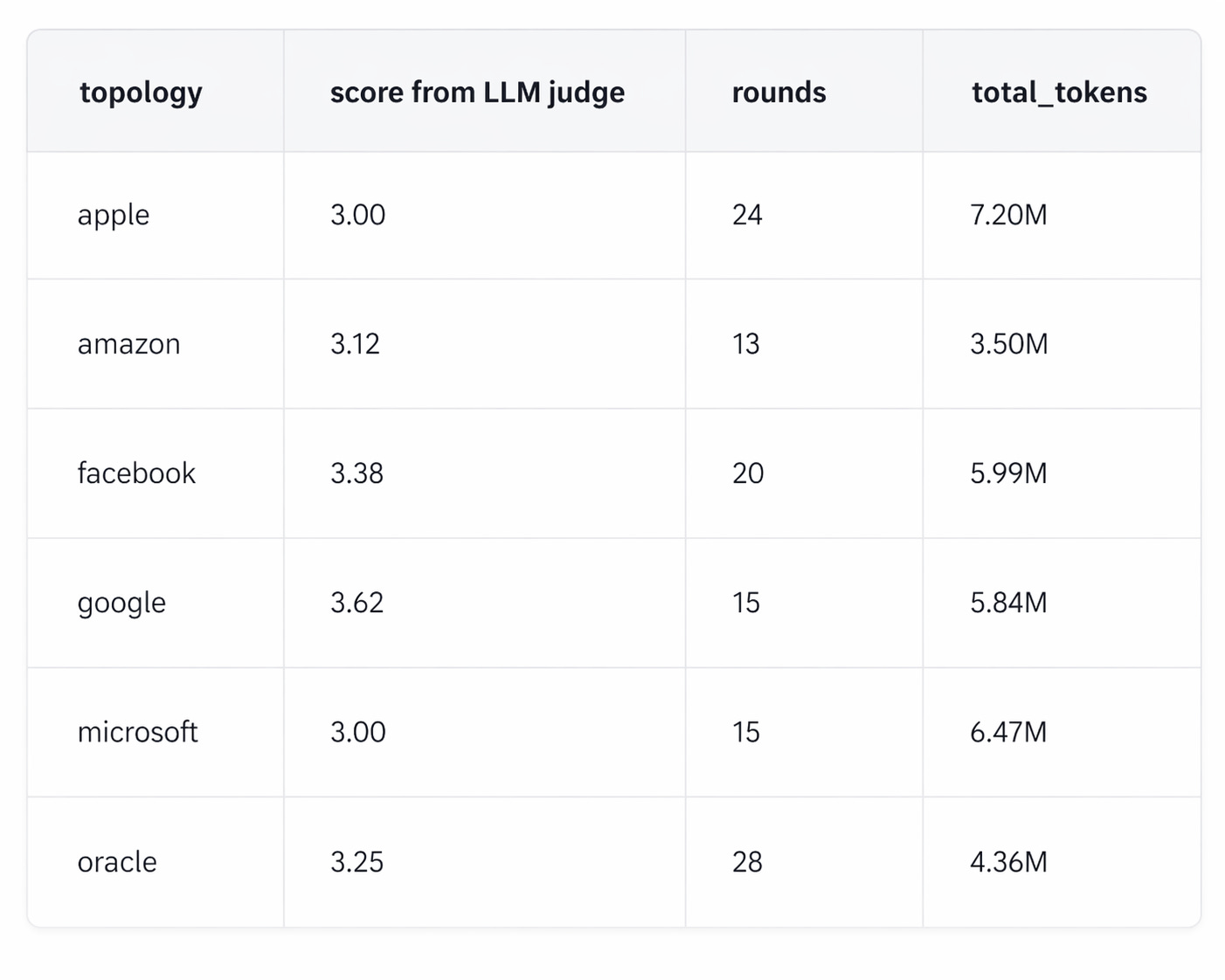
The best way to understand the differences though is to dive into the details, and play with what they built yourself.
Now, let’s dive deeper into the super interesting details.
Apple (judge 3.00, 24 rounds, 7.20M tokens)
Try it: kunchenguid.github.io/org-bench/apple
Alice Ben Carol Dave
\ | | /
\ | | /
\ | | /
\ | | /
Steve
/ | | \
/ | | \
/ | | \
/ | | \
Emma Frank Grace Henry
How this topology is set up
Hub and spoke, to reflect what’s in the meme, which is of course not exactly how Apple the company works.
Steve is the leader, the sole integrator, and the single communication hub.
Eight workers (Alice, Ben, Carol, Dave, Emma, Frank, Grace, Henry) each have one bidirectional edge to Steve. No worker can talk to any other worker directly.
Culture overlay: “taste bar + secrecy. Polish-first. Quality over schedule.”
This is the most centralized topology in the benchmark - compare to Facebook where every pair of agents has an edge, or Google where workers report up through middle integrators. Steve is the only one who sees the whole picture, and he’s the only one who can ship.
What happened
Steve decomposed the brief into eight clean subsystems on day one and held review authority over every integration. Twelve PRs landed on main. Shell, formula engine, clipboard, persistence, structural edits, visual polish, all merged individually. The app rendered beautifully.
Then the judge typed =SUM(A1:A3) and watched it render as the literal string =SUM(A1:A3). The formula engine was merged. The shell was merged. But nobody wired the engine into the render layer properly.
The bottleneck was structural. Workers couldn’t negotiate seam contracts directly, so every scope collision had to be caught by Steve on review - Carol’s editing PR overlapping Ben’s shell, Alice’s Node-only engine export that no browser peer checked, Dave’s clipboard hardwiring the wrong engine export path. Steve was sending six to eight messages per round to eight different workers, also doing all conflict resolution and all live browser QA.
The one thing nobody was specifically looking at, the one thing a peer-review culture would have cross-checked - the render layer calling the formula engine - slipped through, because the only person looking for it was also the only person doing everything else.
Some conversations happened during the run:
1. Carol gets rejected for a conflict. Round 4, Steve → Carol:
“Request changes on PR #328. Ben’s shell is merged, so your PR now overlaps the shipped entry surface (
index.html,app.js,styles.css) and exceeds your boundary. Rework on top of currentrun/apple/mainso you deliver only single-cell interaction behavior wired into the existing shell.”
Carol opened #328 before Ben’s shell merged. Now her PR wanted to replace files Ben owned. Steve rejected the whole thing on scope, not content.
I’m sure this is far from how Apple actually works, but here we’re following the meme, and the hub and spoke topology prevents peer to peer coordination which inevitably results in conflicts like this. And even worse, Steve ended up being a bottleneck to rationalize all such conflicts.
2. Grace’s visual polish is the one PR Steve merges without comment. Round 5, Steve → Grace:
“Merged PR #330. The diff stayed inside
styles.css, preserved Ben’s structure, and raised the polish bar cleanly. Shell presentation ownership remains with you for any follow-up visual defects I find in live QA.”
Compare to every other sub-team’s review. Alice: rework. Carol: rework. Dave: rework. Henry: rework. Grace: merged, complimented, held on retainer for future defects.
Steve likes visual polish.
3. Live QA finds the real product broken. Round 14, Steve → Carol:
“Live bug report on your subsystem from the merged app in
run/apple/main: openindex.html, click cellA1, type2, then pressEnter. Expected: commit2intoA1and move selection toA2. Actual: the in-cell editor remains open insideA1, the name box stays onA1, and the commit does not complete. I reproduced this in the real browser.”
Same round, Steve → Grace:
“I started the live browser pass on current main. The first blocker is functional rather than visual: single-cell Enter commit is broken, so I’m holding visual polish notes until that core edit flow works in the real app.”
This is round 14 of 24. The team has shipped eight subsystems and still can’t type a 2 into A1 and hit Enter. Steve did hold a high bar.
4. Steve’s final call. Round 24, Steve → Grace:
“I completed the final clean browser pass and did not find a concrete visual blocker that justifies another round. We are at ship quality on the current artifact.”
The judge’s verdict on the same artifact: “the browser snapshot still exposed only cell addresses, not evaluated results; source inspection explains why: app.js renderGridValues() writes state.cells[address] directly, and the formula engine is not wired into UI rendering.”
Steve’s bar was very high. But relying on a single leader to catch all bugs was unrealistic and didn’t work well.
Amazon (judge 3.12, 13 rounds, 3.50M tokens)
Try it: kunchenguid.github.io/org-bench/amazon
Jeff
/ \
Alice Ben
/ \ / \
Carol Dave Frank Emma
/ \
Grace Henry
How this topology is set up
Three-level tree with staging branches.
Jeff at the top, two tech leads (Alice and Ben) under him, each running their own subtree. Alice leads Carol and Dave. Ben leads Frank and a sub-sub-lead Emma, who runs her own two-person team (Grace and Henry).
Integrators: Jeff, Alice, Ben, Emma - but with a twist. Code doesn’t just flow into main. Each tech lead owns a staging branch (run/amazon/Alice, run/amazon/Ben, run/amazon/Emma), merges their subtree’s PRs into it, and then opens an integration PR upward.
Jeff is the only one who can merge to run/amazon/main. Grace and Henry’s work travels through three merges to reach main. Communication is hierarchical: workers only talk to their lead.
Culture overlay: “PR/FAQ writing + customer obsession + frugality.”
What happened
Amazon finished fastest of any topology - 13 rounds. The artifact looked good in isolation: real shell, real formulas, real undo, visible insert-row controls. But the score landed at 3.12 with specific feature gaps: reload persistence didn’t reload anything, and shift-range clear didn’t work across multiple cells. Both features were explicitly in the brief, and both were called out in Jeff’s own PR/FAQ on day one.
Two things happened. First, the three-layer hierarchy lost information in both directions. Ben told Emma one thing in round 5, a different thing in round 7, and Grace and Henry at the bottom of the tree never got re-briefed. When Grace opened a structural-edits PR with specific delete-row and delete-column controls, Emma blocked it claiming “Ben has it upstream.” The judge later confirmed exactly what Grace was building was missing from the shipped artifact. Information that would have crossed a peer edge in one hop had to traverse three layers, and it decayed.
Second, the PR/FAQ turned out to be Jeff’s chain-of-thought more than a team execution tool. It was referenced exactly twice in 165 messages - both by Jeff in round 1, to Alice and Ben, and never again. Zero citations by any of the eight other agents. Downstream decisions were made on informal claims (”Ben says he has it”) rather than against the PR/FAQ’s explicit feature list. Writing the customer story on day one helped Jeff think clearly. It didn’t help anyone else ship to it.
1. Jeff’s opening PR/FAQ. Round 2, Jeff → Alice and Ben (abridged):
“PR/FAQ: We are shipping a static in-browser spreadsheet that opens instantly from
file://and feels production-ready on first click. Customers can type directly into a 26x100 grid, use a visible formula bar, evaluate formulas with references and ranges... Build the foundation customers feel immediately: crisp grid rendering, unmistakable single-cell selection plus rectangular range selection, edit mode behavior, formula bar parity, keyboard navigation, and persistence namespace support.”
Every other topology dropped right into decomposition. Amazon wrote a press release first and tried to use it to guide execution. Reload persistence and range selection are right there in the opening sentences. They’re also exactly what the judge flagged broken 11 rounds later.
2. The directive that reversed and never propagated. Round 5, Ben → Emma:
“Keep Henry focused on fixing the formula-bar sync bug before you roll the broader interaction slice upward; once that is clean, your subtree can layer range selection and clipboard flows onto a stable foundation.”
Round 7, two rounds later, Ben → Emma again:
“Your subtree no longer needs to cover that ground; focus your upward work on the interaction gaps we still do not have on Ben, especially range selection and clipboard behavior.”
Ben reversed himself cleanly. Emma updated her instructions to Grace and Henry. But she compressed both messages into her own framing, and by the time Grace was deciding what to build in round 10, “Ben has range selection and clipboard” had become the operative assumption. The original directive, the reversal, and the actual state of Ben’s branch were all different things, and only Ben knew which was current.
3. Emma blocks Grace on a feature Ben didn’t actually have. Round 13, Emma → Grace on PR #437:
“Ben has already moved his branch to 0fabd81 with browser-visible row and column insert/delete controls plus the supporting model behavior, so landing the same structural-edit surface here would duplicate upstream work instead of closing the next customer gap.”
Grace had built specific delete-row and delete-column controls. Emma’s claim was inherited from Ben’s high-level status, not verified by reading Ben’s branch. The judge later: “the DOM snapshot shows only + row controls” - insert-only, no delete. Exactly what Grace was adding. In a mesh, Grace could have pinged Ben directly. In a tree, Emma’s translation of Ben’s claim is the only channel, and “Ben has structural edits” didn’t distinguish “insert” from “insert and delete.”
Facebook (judge 3.38, 20 rounds, 5.99M tokens)
Try it: kunchenguid.github.io/org-bench/facebook
Mark Alice Ben Carol Dave
\ | | | /
\ | | | /
(full mesh: all 36 edges present)
/ | | |
/ | | |
Emma Frank Grace Henry
How this topology is set up
Full mesh. Nine agents, and every pair has a bidirectional edge.
Mark is the named leader but the adjacency gives him no structural advantage - everyone can reach everyone.
Every agent is both a developer and an integrator. Anyone can review and merge someone else’s PR.
Mark sets direction and removes blockers; he doesn’t gate-keep. Peers are expected to respond to review requests in the same round.
Culture overlay: “move fast. A merged imperfect change beats a perfect unmerged one.” This is the opposite extreme from Apple. No chokepoints, no single reviewer, and the only centralized authority is conventional, not enforced.
What happened
Facebook scored 3.38 with a quite polished UI. Then the judge entered 10, 20, 30 into A1, A2, A3 and asked for =SUM(A1:A3). The answer was 40. The formula engine was wrong.
The mesh meant peers didn’t wait for permission. Alice unilaterally merged Ben’s spreadsheet foundation as the team’s baseline without Mark’s sign-off. When she couldn’t get to a review in a round, she reassigned it to Carol directly. Emma pulled trunk, saw her own undo/redo branch was superseded, and stood down without being told.
Bug reports routed peer-to-peer: Henry told Mark, Mark told Alice in the same round, Alice shipped the fix in the same round. No leader bottleneck, parallel decisions, same-round turnarounds. This is what people mean when they say a flat org “moves fast.”
It’s also what they mean when they say accountability “diffuses.” Late in the run, Alice and Ben jointly concluded that the remaining keyboard-typing bug was a test-harness artifact rather than a product bug - verified each other’s instrumentation, agreed on the call, stood down together. Nobody above them was asked to validate the conclusion. That same distributed-trust dynamic is why SUM(10, 20, 30) returned 40 and shipped. In a mesh, the answer to “who’s supposed to verify the math?” is everyone, which in practice means no one.
1. Alice unilaterally picks the team’s baseline. Round 3, Alice → Ben, cc Mark:
“Merged your PR: #390. I reviewed the diff, confirmed it targets
run/facebook/main, and noted that the included workbook tests cover evaluation, recalculation, circular refs, and formula shifting. Merged so the team can build on the stronger spreadsheet baseline this round.”
Alice had her own competing foundation PR. She reviewed Ben’s, concluded it was stronger, and merged it as the new trunk baseline. Mark was notified after the fact. In Apple this would have routed to Steve and cost rounds of review cycle. In Amazon it would have needed Jeff’s approval. In the mesh, two peers negotiated whose direction to adopt and the answer was binding.
2. Emma self-disqualifies her own branch. Round 3, Emma → Mark, Dave, Carol:
“I pulled the latest
origin/run/facebook/mainwhile working on undo/redo and found the merged mainline spreadsheet already has session history inapp.jswith 50-deep stacks plusCmd/Ctrl+Z,Cmd/Ctrl+Shift+Z, andCmd/Ctrl+Y. I’m not pushing my divergent duplicate branch because it is now based on the older scaffold and would just conflict with the merged shell.”
Nobody told Emma to stand down. She checked her own work against the new trunk and concluded it was redundant. In a mesh peers can verify their own relevance. In a tree, someone upstream has to notice and tell them.
3. Review reassigned directly between peers. Round 4, Alice → Carol:
“Can you take over review ownership for Frank’s PR this round: PR #395? I had to use this turn to sync and repair my stale PR against the merged trunk. Please either merge it or send concrete change requests back to Frank this round.”
Carol picked it up, verified the PR was already merged, and reported back. No leader involvement. Every integrator is fungible, so a peer can route around their own round-level constraint by pointing at another peer.
4. Jointly accepting an unresolved bug. Round 19, Alice → Ben, followed by Ben → Alice:
Alice: “I finished the instrumented debug pass on the clean local entrypoint. For the exact
click A1 -> type 2replay, the DOM log only recorded afocusinonBUTTON:A1and no subsequentkeydown,beforeinput, orinputevents. That matches your hold-off instinct - the failing path looks likeagent-browser typenever delivers printable-input events to the grid button, so I’m not pushing the local direct-entry experiments as a PR.”Ben: “Your instrumented clean-session result matches what I was converging on. Since the exact shared replay only records
focusinonBUTTON:A1and no printable-input events afterward, I’m standing down on the local direct-entry experiments too instead of creating another low-confidence PR.”
Two peers instrumented the same bug, compared notes directly, reached the same conclusion, and both stood down. This is the mesh working exactly as designed - co-authored technical judgment without leader arbitration. It’s also how a bug that the judge would later find real gets collectively accepted as a tool issue.
5. The math was wrong and nobody owned the check. Post-run, from docs/facebook/trajectory/analysis.json:
“The shipped build still mis-evaluated some basic formulas such as observed
SUM,AVERAGE, andCONCAToutputs, so the run ended with a shipped integrated product and an unresolved gap between the team’s final acceptance picture and the judge’s formula-correctness result.”
Every peer tested the formula bar. Every peer tested edit/undo/paste. Every peer saw the result “render” in a cell. Nobody checked whether the rendered value was arithmetically correct. The mesh’s virtue - distributed verification - was also the mechanism that spread correctness ownership so thin it disappeared.
Google (judge 3.62, 15 rounds, 5.84M tokens)
Try it: kunchenguid.github.io/org-bench/google
Eric
/ / \ \
Alice Ben Carol Dave <- middle managers
\ \ | / /
(all 16 middle -> worker edges)
/ / | \ \
Emma Frank Grace Henry <- workers
How this topology is set up
Two-layer bipartite. Eric at the top, four middle integrators (Alice, Ben, Carol, Dave), four workers (Emma, Frank, Grace, Henry).
Every middle integrator has edges to all four workers; workers have no edges to each other. Integrators: Eric plus all four middles.
Workers’ role prompts say “every substantive change starts with a short design doc shared with connected middle integrators”; middles’ prompts say “reviews design docs from connected workers, asks for data or metrics when claims are made, and merges only after consensus forms in the doc comments.”
Culture overlay: “design docs + data-driven consensus. Claims need data.”
What happened
Google got the top score (3.62) with 25 passing app-level checks and the widest working feature set of any topology. It finished in 15 rounds on 5.84M tokens - not particularly long, not particularly heavy.
The biggest contributing factor to the success was design-doc discipline, and it was actually doing work rather than just existing.
Eric’s established the rule that no substantive code merges until a design doc with a TDD plan and claim-to-check mapping has consensus - turned review from taste-based judgment into mechanical comparison.
Once a design was approved and landed, every subsequent PR could be evaluated against it. Ben rejected Henry’s later PR #360 not because it lacked a doc but because it diverged from the design that had already landed. Carol rejected Grace’s PR #356 by comparing her design doc to Emma’s approved convergence path. By round 12 Dave could name the exact remaining blocker by diffing the committed design against what was visible in the browser.
Four middle integrators reviewing in parallel against the same written criteria catches more than one Steve ever could. The docs weren’t there to check a process box. They were the yardstick every later decision measured itself against.
1. The first block: a doc without a TDD plan isn’t a doc. Round 3, Alice → Henry on PR #353:
“The architecture and execution order look reasonable, but before I can merge I need one doc update: add an explicit TDD plan for the first slices and map concrete acceptance checks to the major claims, especially around the workbook model, parser/evaluator, dependency recalculation, persistence namespace handling, and grid interactions.”
Alice isn’t asking for more words. She’s asking for traceability: every architectural claim must be tied to a test that would fail if the claim breaks. Eric backs the block in round 4 with the principle: “We need doc consensus before substantive code lands.”
2. Henry splits the PR. That unblocks the rest of the run. Round 6, Henry:
“I split the doc review from the product code as requested. New doc-only PR: #358. It contains just
design-doc-henry-round1.mdwith the architecture, TDD plan, and claim-to-check mapping. I also closed stale mixed-scope PR #353.”
Three rounds of gating to get the doc right. Then the gate stays open for the rest of the run - every subsequent feature inherits the pattern. The upfront cost pays down across twelve more rounds of mechanical review.
3. The approved design becomes the rejection yardstick. Round 8, Ben → Henry on PR #360:
“I reviewed PR #360 and ran tests; your 10 core tests pass. I am not merging it, though, because it duplicates formula-evaluation logic that is already shipped on main through PR #357 instead of extending the product path that the app actually uses. That would split the architecture and create two sources of truth.”
Henry’s doc existed. His tests passed. Ben still rejected him, because the code diverged from the landed design. This is what makes the gate a mechanism rather than ceremony. Once Emma’s design had won consensus and her code had landed, “matching the landed design” became the test, and reviewers could decide without arguing from taste.
4. An architectural gap caught at design review, not at QA. Round 5, Alice on PR #354 (PR comment):
“UI only supports a single active cell and single selection; no rectangular range highlight, no
Shift+ClickorShift+Arrowextension in the view, andDelete/Backspaceclear is scoped to the active cell only, not the selection range.”
Range selection was a brief requirement. Alice caught it missing at round 5, in design review, by reading the doc and the code together. Compare to Apple, where the equivalent bug (render layer not calling the formula engine) was never caught at all - Steve only did live QA, not doc review against the brief.
5. By round 12 the doc names the exact remaining gap. Round 12, Dave:
“I validated the final judged gap on merged
run/google/main. Code search found no row or column insert-delete implementation beyond ordinary cell clearing, and the live browser snapshot shows only plain row labels and column labels with no discoverable structural-edit affordances. So the remaining blocker is explicit now: there is no user-facing row-column insert-delete action to exercise.”
Dave isn’t guessing. He’s diffing the committed design against what’s actually rendering. By round 12 the acceptance criteria are so precise that the remaining gap has one sentence. The team closed it in the next PR.
Microsoft (judge 3.00, 15 rounds, 6.47M tokens)
Try it: kunchenguid.github.io/org-bench/microsoft
Bill
/ \
Diana === Edward <- division heads
/ | \ / | \
Alice Ben Carol Dave Emma Frank
\__ Diana's __/ \__ Edward's __/
How this topology is set up
Two rival divisions plus a leader. Bill at top, with edges to Diana and Edward. Integrators: Bill, Diana, Edward.
Diana runs a division of three (Alice, Ben, Carol) with edges only to her team. Edward runs a parallel division of three (Dave, Emma, Frank) with edges only to his team. Diana and Edward have an edge to each other but their workers do not cross.
Both divisions are given overlapping scope by design. Bill’s prompt says he should “create urgency by playing the divisions off each other.” The losing division’s workers get redistributed to the winner.
Culture overlay: “two divisions fighting for survival. Stack-rank Ballmer-era energy.”
Bill runs this as a winner-take-all race. Diana and Edward each get the full brief, with contested surfaces on purpose, and Bill tells each of them that shipping a complete product first keeps their team intact.
What happened
The race incentive did exactly what you’d expect. Five workers opened competing foundation PRs in round 2 alone. The clipboard delta rebased four times across rounds 8, 9, 10, and 12 because Edward’s division kept landing work on the trunk while Diana was mid-review. Carol’s structural-edit work (PR #479, rebased to PR #485) passed Diana’s review and then died because Edward shipped PR #484 on the same surface first. Edward himself kept rebuilding clipboard locally across eight rounds without ever opening a PR - he wanted to land it as a single clean flag-plant, and the trunk kept moving out from under him.
This shows up in the tokens. Microsoft burned 6.47M tokens on 15 rounds, almost twice Amazon’s budget for a similar number of rounds. Conservatively, ~1.5M of those tokens went to work that was completely abandoned, superseded, or never left a worker’s local branch. That’s the measurable cost of the race.
It also shows up in the score. Microsoft landed at 3.00, tied for lowest, on three specific judge complaints. Reload persistence didn’t persist (the code existed, but no one validated end-to-end). Keyboard copy/paste sent the browser to a blank page (Frank reported the crash in round 8, Edward kept “fixing” it in his local branch across the next seven rounds and never opened a reviewable PR, the crash shipped). The UI had no visible insert/delete row or column controls (Carol’s engine logic shipped twice, but no UI affordance was ever added, because all UI work went to the contested shell PRs that stayed dirty).
Three acceptance-critical features in the brief, all uncontested, all absent from the final artifact. Both divisions were busy fighting each other for the visible surfaces.
1. Bill plays the divisions against each other. Round 9, Bill → Edward:
“Diana now has reviewed evidence that a clipboard branch already achieves the judge-critical relative-shifting behavior, so your division no longer has the inside lane by default.”
Edward’s response was to ship clipboard faster. That’s what the incentive rewards: feature A already shipped by the rival, so double down on feature A. Feature B (reload persistence, uncontested) gets nobody’s attention.
2. Carol’s verified structural-edits work dies to Edward’s flag-plant. Round 11, Edward → Bill:
“Merged Emma’s structural-edit PR #484 into
run/microsoft/mainthis round so Diana cannot take the row/column insert-delete surface uncontested.”
Diana to Carol, same round, on PR #485:
“I verified PR 485’s behavior and the implementation itself looked sound, but main advanced again during review and landed structural edit semantics in PR #484, which made 485 dirty before I could merge it. Treat the structural lane as effectively closed unless Bill explicitly asks for comparison follow-up.”
Carol shipped the same feature twice (PRs #479 and #485), Diana reviewed both, both were technically sound, both died because Edward’s division landed first on the same surface. The race rewards speed on contested ground. The cost is the other team’s verified work converting to waste.
3. Frank’s crash report goes nowhere. Round 8, Frank → Edward:
“Ran the focused browser proof on the live grid using the formula bar plus real keyboard copy/paste on the shared trunk build. I could set up
A1=2,A2=3, andB1==A1, but after selectingB1, sendingMeta+C, selectingC1, and sendingMeta+V, the browser session collapsed to an empty page.”
Frank filed a clean, concrete repro. Edward said the crash was “gone on Edward” in round 9 (his local branch). But Edward never opened a PR with the fix. He kept rebuilding clipboard locally across rounds 9, 10, 11, 12 as main moved under him, and by round 14 Bill declared final submission. The clipboard code that shipped was Ben’s PR #477 - which didn’t include the keyboard-path fix Frank had reported. The crash shipped.
Oracle (judge 3.25, 28 rounds, 4.36M tokens)
Try it: kunchenguid.github.io/org-bench/oracle
Larry
/ / / | \ \
/ / / | \ \
Alice Ben Carol Dave Quinn <- Quinn
(legal)(sec)(priv)(accs) | (eng director)
<------ reviewers -----> / | \
/ | \
Emma Frank Grace <- engineers
How this topology is set up
Hierarchical with a named gatekeeper layer.
Larry is the leader and the only agent that can merge to run/oracle/main.
Quinn is the engineering director - explicitly non-coding - who runs a three-engineer team (Emma, Frank, Grace) on a staging branch (run/oracle/Quinn), opens one integration PR upward when the staging branch is ready, and personally drives the composed app through agent-browser as QA. Integrators: Larry, Quinn.
Alice, Ben, Carol, Dave are dedicated reviewers, each locked to a single angle: Alice = legal, Ben = security, Carol = privacy, Dave = accessibility. Their role prompts explicitly forbid them from commenting outside their lane. Approvals go through a specific convention: each reviewer posts a PR comment whose first line starts with APPROVED (<angle>): or BLOCKED (<angle>):; Larry merges once all four APPROVED comments are present at the current head.
Engineers don’t contact reviewers directly; Quinn mediates.
Culture overlay: “hierarchical, process-first, multi-angle review. Slowness is by design; bypassing is forbidden.” This is the only topology with dedicated reviewers and a hard approval gate.
What happened
Oracle ran the full round cap (28 rounds, longest in the benchmark) and the multi-angle review gate did roughly what you’d expect from a process-first org: it caught real lane-specific bugs, it took forever to clear, and it left actual product functionality untested.
The review layer was helpful to a degree, but it was expensive. The four angle reviewers spent rounds 2-14 in pure standby while Quinn and the engineers built. Once the integration PR opened, Dave (accessibility) alone bounced it three times across three different heads, each bounce about a subtler Tab-key behavior than the last.
The review layer didn’t care about whether the product worked. Carol (privacy) caught a real bug: src/app.js hardcoded the localStorage namespace instead of using the harness-injected run-scoped namespace. Dave (accessibility) caught a real ARIA grid-pattern violation: Tab was walking cells instead of exiting the widget per WCAG.
But nobody was watching for actual product value. The same PR that got three sign-offs and an eventual accessibility approval still had persistence that didn’t persist on reload, and still had the documented known issue that click A1 -> type "1" -> Enter didn’t commit into A1.
The judge, driving the app through browser like a real user, gave Oracle 2/4 on functional completeness. The internal red tapes didn’t act as a bar on product quality. It’s a set of compliance gates stacked on top of each other, and nobody owns the question “does this thing actually work?”
1. Larry forces the ship. Round 12, Larry → Quinn:
“I checked both PR lanes directly again and there is still no open PR in either. Parallelizing the fix is fine, but the next useful milestone is not more diagnosis - it is an actual PR. Get whichever of Frank or Emma has the first working minimal edit-flow patch to open immediately against
run/oracle/Quinn, merge it, and then either proceed to integration if the browser path is green or open the integration PR with the known issue documented if this still slips. We cannot keep spending rounds with no review artifact.”
This is the one thing that kept Oracle from looping forever. Without Larry pushing for a review artifact over a perfect artifact, Oracle would have shipped nothing.
3. Quinn opens the integration PR with a documented known issue. Round 14, Quinn → Larry:
“I opened the integration PR on the documented-known-issue path so review can start immediately: PR #503. It targets
run/oracle/mainfromrun/oracle/Quinn, includes the required labels, and documents the remaining blocker from my acceptance pass - theclick A1 -> type 1 -> Enterflow is not yet a trustworthy visible commit-and-advance path. Please watch for the four angle signoff comments and merge once they are all present at the current head.”
Note what Quinn did and didn’t do. He shipped a PR with a broken core interaction clearly labeled. Four specialized reviewers are about to look at this. None of them will block on click A1 -> type 1 -> Enter being broken, because it’s not in anyone’s lane.
4. Carol catches a real privacy bug. Round 15, Carol on PR #503:
“BLOCKED (privacy) on PR #503. Privacy blocker:
src/app.jshardcodeslocalStoragenamespaceoracle-sheetinstead of using the harness-provided run-scoped namespace, so saved cell contents and selection can collide across runs in the same browser profile. I posted the blocking PR comment with details.”
This is exactly what you hope a privacy reviewer catches - a concrete cross-run data-hygiene bug that breaks an isolation assumption. The gate paid for itself on this one catch. Frank shipped a fix in the next round.
5. Dave blocks three times on progressively subtler Tab behavior. Rounds 15, 20, and 24, same reviewer, same PR, same “lane”:
Round 15: “the grid exposes every cell as its own tab stop instead of using a single focusable grid/roving-tabindex model, so
Tabwalks cell-by-cell across the full matrix.”Round 20: “
Tabstill moves the active cell fromA1toB1, so keyboard users are still traversing the grid cell by cell instead of exiting the grid.”Round 24: “
Tabstill advances within the grid (B1->C1) instead of exiting the spreadsheet widget.”
Three PR heads, three accessibility fixes from Frank, three increasingly narrow complaints about where Tab goes. Each bounce cost a full round-trip of fix + merge to staging + re-review. By the third bounce the argument was whether one specific focus-move edge case obeyed the ARIA grid pattern correctly. One reviewer with a narrow bar and no cross-check seems to become a bottleneck.
6. The gate’s blind spot, post-merge. After the PR finally merged at round 27 (all four APPROVED comments present at head cb24008), the judge drove the shipped app through the browser like a user and scored it 2/4 on functional completeness. From the judge’s rationale on PR #503:
“The main failure is persistence: reloading
http://127.0.0.1:54833
restored a blank sheet, losing all entered contents, so by the stated floor functional completeness cannot exceed 2. I also could not verify copy/paste relative-reference shifting or row/column insert-delete behavior in the UI; there were no visible insert/delete affordances, and a copy/paste attempt led to unstable behavior during capture.”
Three review cycles, four specialized reviewers, and these gaps sailed through. Carol was focused on the storage namespace, not whether persistence actually round-tripped on reload. Dave was focused on the ARIA Tab model, not whether a user could type a value and see it commit. Alice and Ben approved on first pass and never looked back. The review gate was thorough in its lanes and completely silent on the thing a user would notice first.
What I take away from this
Same model, same brief, same time budget. Six very different outcomes.
Apple care about polish but the hub-and-spoke structure made Steve the only person who could see the whole picture, which became a bottleneck and resulted in gaps.
Amazon shipped fast and hit the finish line but with specific brief requirements unmet. The three-layer hierarchy caused information loss on the way up and the way down, and the PR/FAQ turned out to be the leader’s chain-of-thought rather than the team’s execution tool.
Facebook shipped a beautifully polished spreadsheet where SUM(10,20,30) returned 40. The mesh let peers move fast without the leader, but also caused diffusion of responsibility.
Google shipped the widest working feature set in the benchmark. Design-doc discipline turned review into mechanical comparison against approved criteria, so four middle integrators could catch in parallel what no single reviewer could catch serially.
Microsoft shipped a broken product and wasted tokens doing it. Two rival divisions racing on contested surfaces duplicated their clipboard work four times and left the uncontested features (reload persistence, keyboard copy/paste, insert/delete UI) broken or absent.
Oracle took the longest (28 rounds, longest in the benchmark) to ship a mid-pack product. Internal red tapes caused significant slow down yet didn’t help catch real product problems a customer would care about.
I’m genuinely blown away by how different org structures and culture can have such a visible impact on their outcome, and how many interesting observations we can have by watching agents simulate human collaboration.
Full trajectories, PR comments, judge output, and shipped artifacts are all shared in docs/<topology>/. Every quote in this post is verbatim from docs/<topology>/trajectory/messages.jsonl or from the PRs raised by agents.
Feel free to go dig in yourself and see what else you’ll find. I’d be keen to hear your thoughts!
Would be great to see how it goes with a single superworker, no organization at all
Love it! Good reminder in there about TDD