
Evaluating the Effectiveness of Programming Languages for Agents
And how to pick the best one

Here is an old programmer argument that never dies: which language is best.
I’m not here to settle the holy war, but as we use agents more and more, I thought it’s at least useful to gather empirical evidence of how programming languages affect the performance of agents.
What I thought would be easy ended up taking a whole month of attempts and thousands of dollars worth of tokens, but I finally have it.
Some interesting findings to get a taste for what this tells us:
Rust is the best easy-task language but has the steepest drop on hard tasks.
Static typing appears to pay off on hard tasks.
The legacy languages, C and Java, perform the worst.
Letting your agent choose the language is a good default.
Now let’s dive in.
Setup
The benchmark uses ProgramBench from Facebook Research (repo, paper): asking agents to recreate real world programs.
Each task hands the agent the docs and observable behavior of a real tool (htop, sd, quickjs, brotli, and so on) inside a sealed sandbox with no network, with the source and tests hidden, and asks it to reimplement the tool well enough to pass a large hidden test suite. It is a good benchmark for this question because the tasks reflect real world requirements very well, and are difficult enough to push the agents very hard on all dimensions. The tasks can also be solved by any language.
The tasks and test harness are from ProgramBench as-is; my contribution is the experiment design layered on top. Benchmarks like this are usually used to evaluate different LLMs. But I realized they can totally help evaluate differences in the agent harness as well.
So I took one model and harness, gpt-5.5 in Codex, held it fixed, and had it solve the same set of programming tasks eight separate times, once in each of eight mandated languages: C, Go, Rust, Java, JavaScript, TypeScript, Python, and Ruby. Then a ninth arm, free choice, where the model picks the language itself per task.
Because the sandbox has no network, each arm ships with an offline mirror of its language’s most popular libraries: roughly the top 100 packages per ecosystem (by download rank where one exists, like crates.io and PyPI, or a curated widely-used set where it does not, like npm and Go modules), vendored into a read-only tree that the toolchain resolves against so real dependencies still work offline. This is what keeps the comparison fair, so a language is never penalized just because its ecosystem assumes a package manager.
How I measure it
Every task produces a per-task pass rate: the fraction of that task’s (non-ignored) hidden tests that passed. I report two things.
Mean pass rate, broken down by task difficulty (easy / medium / hard), as the primary way to communicate the result.
A threshold-free significance test (paired Wilcoxon signed-rank, Holm-corrected) on the continuous per-task pass rate, for the “better / worse” claims.
I break the mean down by difficulty rather than reporting one aggregated number because the tasks span a wide difficulty range, and a single mean weights every task equally, conflating “did well on trivial tasks” with “made progress on hard ones.” Difficulty is defined as the cross-arm mean pass rate on each task (low = hard), split into equal-count thirds.
Denominator: n = 192. I blocklisted 8 tasks that seem to have problems in the test harness: 7 structurally broken (4 fill the disk and wedge the test daemon; 3 produce identical failures across every arm regardless of submission) plus dsq, which can only be satisfied by delegating to a SQL engine bundled in the language runtime that no sandbox strip can remove (see Caveats).
The results
All nine arms compiled at essentially 100%, so the spread is entirely in how much of each task got solved.
The clearest way to see the comparison is cost versus quality at each difficulty level: each point is one language, x is token cost ($/task), y is mean test pass rate, and the ideal corner is top-left (cheap and high-quality). The dashed lines are the medians.
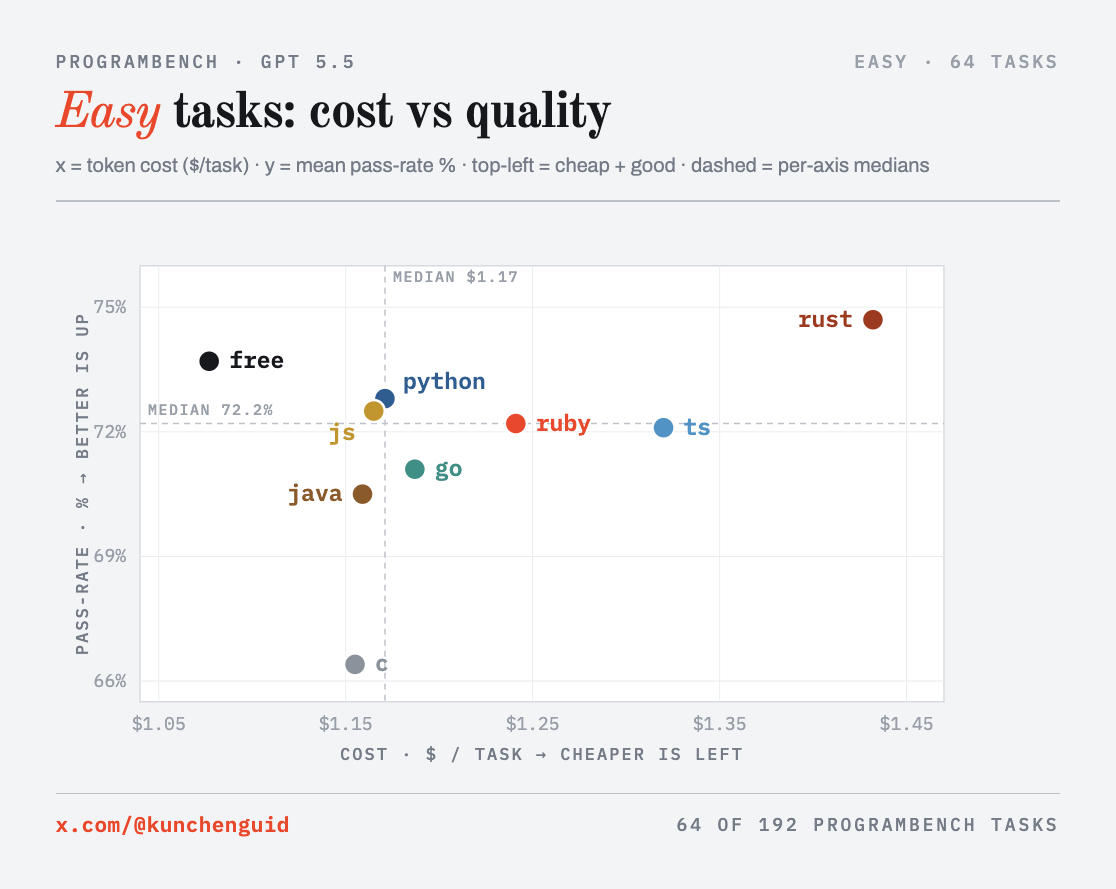
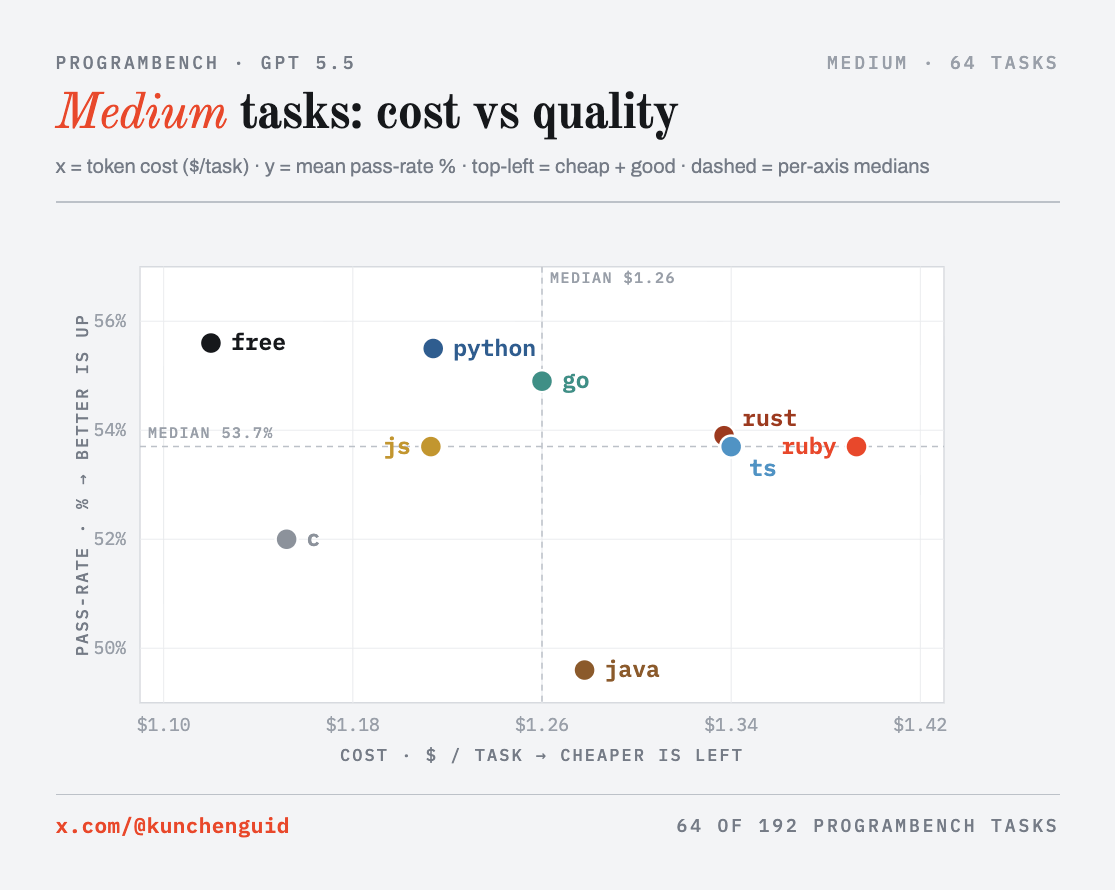
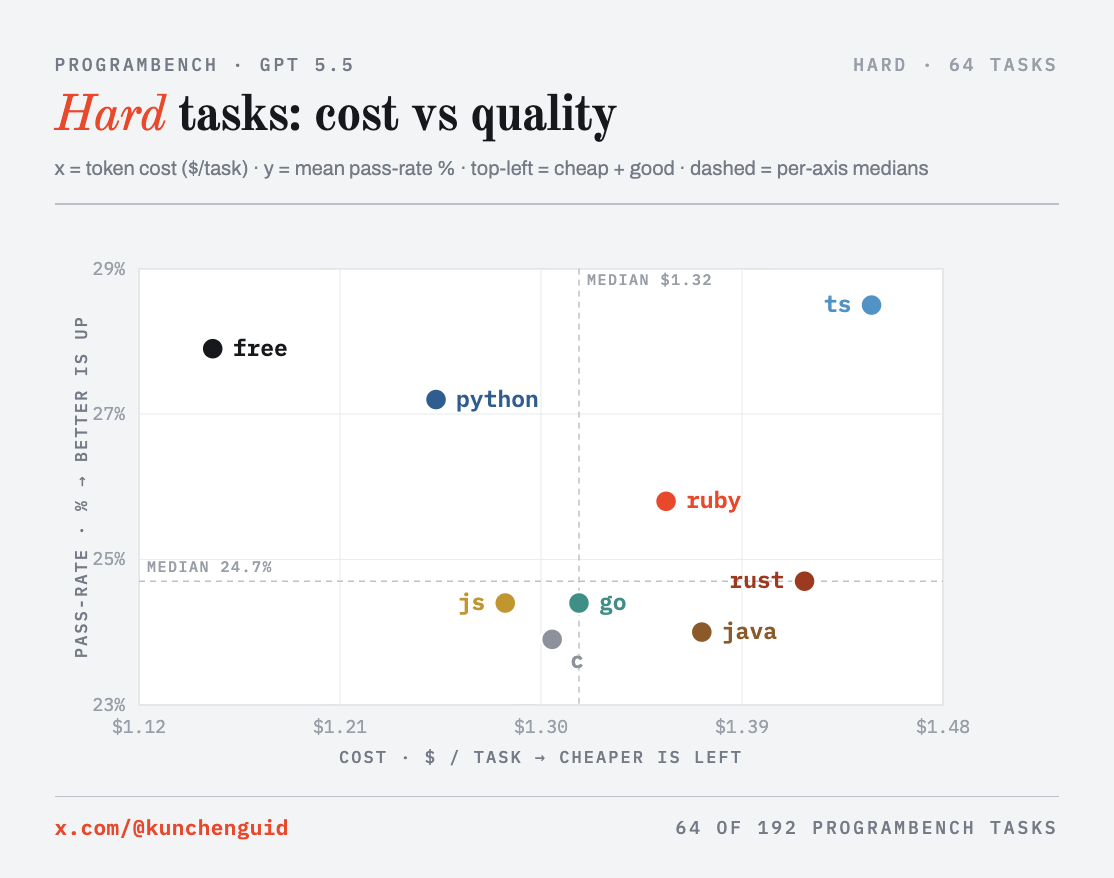
Three things to read off the panels.
First, the quality axis is a tight cluster: at every difficulty the top six or seven languages sit within a few points, and the paired test doesn’t separate them in a statistically significant way. The clear signal is at the bottom: free choice is statistically ahead of only c and java (Holm-corrected paired Wilcoxon, c p < 0.0001, java p = 0.0001), and c and java are the two worst arms.
Second, watch rust move across the panels: on easy tasks it is the best quality but sits far to the right (most expensive), and on hard tasks it slides down into the low cluster, while free, python, and ts hold the top.
Third, free choice is the only arm in the cheap-and-good corner of all three panels at once (below the median cost and above the median quality in every tercile). That consistency is also why it ends up marginally the highest-scoring arm on mean pass rate, and the cheapest. The rest of the post is why each of these happens.
Rust: best on easy, steepest drop on hard
Rust is the best easy-task arm (74.7) and falls into the low cluster on hard tasks (24.7), the steepest easy-to-hard drop of any language (about 50 points).
Why it wins the easy tasks: it reproduces the exact contract. Most of the easy tools in the ProgramBench eval set are compiled CLIs, and Rust is great at it. On sd (a sed-like tool) Rust scored 91.7%, the best of any arm, by pulling in the real regex crate, where C hand-rolled regex and diverged down to 76.7%.
That precision is a compiled-language tendency, not a Rust-only one. On hex (a hex dumper) three of the four compiled arms cluster at the top (go 88.6%, c 87.7%, rust 86.8%) and leave Python at 66.2%; the exception is Java, which landed at 62.5%, below Python, a reminder that compilation is no guarantee. The Python gap has one root cause: attached short flags. Python’s hand-rolled parser only matched -a as a whole token, so hx -ar file (array output) was rejected with error: unexpected argument '-ar', and the whole array-output test family failed; the three arms at the top split -a + value r exactly like the original.
Why the lead doesn’t hold on hard tasks: its one advantage doesn’t transfer. The important nuance, because it is easy to overclaim here: Rust is not the only language that’s bad on hard tasks. It scores 24.7 there, in the low cluster with most arms, and js (24.4), go (24.4), java (24.0), and c (23.9) are all at or below it. On a hard task the substance is a domain engine (an image decoder, a query language etc), and a full re-implementation is difficult.
But other languages hit the same wall: on quickjs, a whole JavaScript interpreter, the from-scratch arms all cratered (rust 3.1%, go 3.6%, c 3.7%, java 4.6%), and only the arms that could lean on the host JavaScript runtime survived (free 62.8%, js 59.9%, ts 59.8%). Rust just had the most to lose, because the advantages it had on easy tasks don’t help solve the challenge of getting a full re-implementation right.
And it pays the most to do it. Rust runs more build cycles than any arm (it pays a full cargo build --release on every fix, where a scripting arm re-runs the interpreter for free), and it is the most expensive arm overall ($1.40/task) and the priciest on hard tasks ($1.42/task).
TypeScript edges JavaScript on hard tasks, and it really is the type checker
The TypeScript-versus-JavaScript pair is a gem hiding inside this study: same model, same tasks, same sandbox, and both arms compile down to JavaScript run by the same Node.js. So this becomes a good study for the benefit of static typing, because the only structural difference is that the TypeScript arm has to clear tsc before it can run.
Overall they tie. TypeScript scored 51.4 to JavaScript’s 50.2, a +1.2 gap that is not significant (paired Wilcoxon p = 0.65), and the two split individual tasks nearly evenly (TypeScript wins 98, JavaScript 92). But if we zoom in to the hard tasks, TypeScript beats JavaScript by +4.1 (28.5 versus 24.4), and within that tercile TypeScript wins 40 of the head-to-head matchups and loses 23.
What tsc catches are real type errors. On cppcheck (17.5 versus 3.2) the argument parser returns Options | string, a string on bad input, and tsc would not let the agent read fields off the result until it handled the error case; the same build also caught an accidentally duplicate-pasted source file (36 TS2393: Duplicate function implementation errors) that the agent then deleted. On angle-grinder (43.0 versus 27.3) tsc inferred a token reader’s result as a union type and rejected calling .toLowerCase() on it (TS2339: Property 'toLowerCase' does not exist), forcing the agent to guard the non-string case before using it; the JavaScript version ships without that guard. On dropbear (an SSH server, 64.2 versus 32.2) the JavaScript submission ships a program that fails to come up at all: 243 of its results are hard errors (Node MODULE_NOT_FOUND on its own entrypoint, and a daemon that never prints its readiness banner), against 54 for TypeScript, whose checked-and-built pipeline produced a runnable artifact. These are the broken-import, unhandled-union, duplicate-definition crashes that type checking can stop.
The surprise is that the agent gets this almost for free, not by typing carefully. Fewer than a third of TypeScript submissions (28%) enabled strict, almost all used any at least once (median 5 uses per submission), and noUncheckedIndexedAccess was on in zero of 192. The catches above came from tsc‘s default inference (it derives a union type from control flow with no annotation) plus a mandatory gate: TypeScript’s compile.sh runs tsc under set -e and refuses to emit ./executable until the program type-checks, where JavaScript’s compile.sh just writes whatever was authored and ships it. The agent treats TypeScript as JavaScript-with-a-checker, and the checker still pays off.
So the finding is honest and bounded: on hard tasks, tsc‘s baseline type checking plus a mandatory compile gate buy a small but real edge by catching crash-class bugs the JavaScript arm ships to a failing run - and they do it almost for free, in spite of the agent’s loose typing, not because of disciplined types. It is shallow runtime-error prevention, not a deep correctness guarantee, and it mostly shows in hard tasks.
C and Java: the two worst arms
C (47.4) and Java (48.0) are the bottom two arms, and the only two arms significantly below free choice (Holm-corrected paired Wilcoxon: c p < 0.0001, java p = 0.0001; every other arm is statistically tied with free).
C is a high-variance specialist that loses the median. On some tasks it is the outright best arm: on brotli (a compression tool) it scored 36.7% where no other arm reached even 2%, the bit-level encoding work playing straight to its strengths, and on flamelens (a flamegraph TUI) its 54.0% beat the whole field by 9 points. But it is last on the easy tercile (66.4) and last on the hard tercile (23.9), because the median task makes C hand-roll the infrastructure every other language imports, and each reinvention causes a drop. The ecosystem disadvantage is real. On nomino (a regex renamer) it hand-translated the original’s named groups into POSIX regexec and hand-wrote a JSON map scanner, and scored 38.3%, near the bottom of the field on the regex-semantics mismatch. On grex it parsed -x and -c into its options struct but never implemented them, so the verbose/colorize tests found bare output, and it landed last on that task (49.1%). The easy tercile is full of text and parsing CLIs like that, which is why the language that crushes brotli is also dead last when the easy task is a JSON-or-regex tool.
Java’s problem is the contract tail plus JVM idioms. Java’s low placement is genuine wrong-output, concentrated in CLI-flag and TUI tasks. On htop (58.6% to C’s 90.6% on the same task) it wired up every short flag to consume its next token except -u, which read $USER and ignored its argument, so -u root fell through to invalid option -- 'root'. On entr it printed help to stderr (failing assert b'summary:' in stdout) and used a JVM shutdown hook for cleanup, so Ctrl-C produced exit code 130 where the test wanted 0 or 2, and it scored 37.4%. On hwatch it parsed the --batch flag but never acted on it, running an unbounded watch loop instead of the bounded batch path, so the --stdout batch tests timed out with empty output and it scored 24.3%, far below every other arm. The throughline is Java’s verbose stdlib and JVM conventions: more boilerplate per feature means fewer of the small contracts land, and idioms like shutdown-hooks-to-exit-codes and stderr-default-help actively violate the native CLI behavior the tests encode.
Neither is a disaster on any single task, but both reliably leave points on the floor relative to other languages, at no cost advantage. For agent-written, behavior-matching work, I would probably just avoid C and Java unless there’s a clear reason to reach for them.
Does matching the tool’s original language help?
Every task reimplements a real tool, and that tool was originally written in some language; ProgramBench records it in each task’s metadata. The distribution is lopsided: of the 192 tasks, 105 are Rust tools, 43 Go, 31 C, 12 C++, and 1 Haskell. Every single one is a compiled or systems language; not one is natively written in Python, JavaScript, TypeScript, Ruby, or Java. So four of the eight mandated arms are never working in the tool’s home language.
So does matching the tool’s language actually help? A little, and unevenly. On the tasks whose tool is its own language, a mandated arm beats the average of the other mandated arms by:
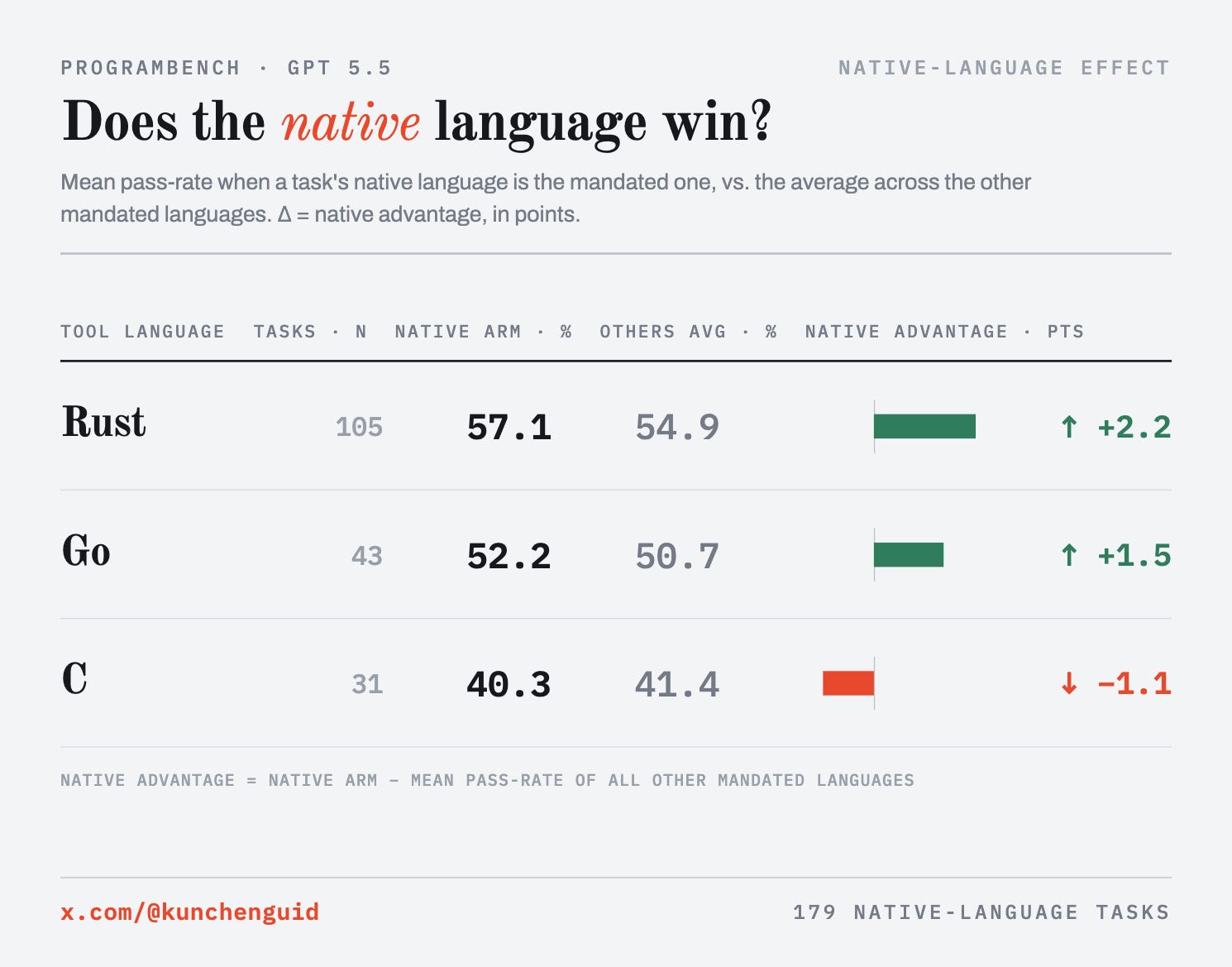
Rust and Go get a real but modest native bump. C is the exception, and for the same reason it finishes last overall: C’s penalty is a missing-batteries tax (hand-rolling JSON, regex, text handling) that matching idioms cannot pay off, so C does no better on its own tools than the other arms do. Across all native (arm, task) pairs the advantage averages +1.4: present, but small.
Interestingly, when given free choice, the model picked the native language only 12% of the time; it defaults to Python on ~80% of tasks, including the Rust and Go tools where matching would have paid. But even then, free choice didn’t do too badly.
Free choice is a safe default
Free choice is the cheapest arm ($1.12/task), it is statistically tied with the top of the cluster on mean pass rate (52.4, indistinguishable from rust, python, go, ts, and ruby), and it never collapses. That combination makes it a good option to reach for when you do not have a strong choice upfront.
The picking is a smart, adaptive default. It chooses Python on ~80% of tasks (158 of 192), switches to C for native systems and TUI tools (htop, cmatrix, tig), and to Go for Go-ecosystem tools (every Go-linter task, because the tool analyzes Go code: “the program is errcheck-like, a Go static analyzer; I’m creating throwaway Go packages to compare diagnostics”). It even picks JavaScript when the tool is a JS engine (”use the installed Node runtime as the ECMAScript engine” on quickjs). The picks are legible and adaptive.
Why it is cheapest: no compile-fix loop. On the 158 tasks where it picked Python, free averaged 39 turns and $1.10, versus rust at 45 turns / $1.40 and TypeScript at 42 turns / $1.38 on the same tasks, at statistically equal quality (paired Wilcoxon p = 0.84 vs rust, 0.42 vs ts). The driver is build cycles: per task, rust averages 3.2 failed commands and 2.2 builds, TypeScript 3.2 failed and 3.8 builds, free 1.9 failed and 0.5 builds. On html-to-markdown, free (Python) reached its submission in 18 commands with no build step; the Rust arm ran 42 commands and 7 full cargo builds; the TypeScript arm ran 33 commands and repeated tsc invocations (including one that failed on error TS2300: Duplicate identifier 'Node'). Python has no compile step, so those turns simply do not exist. That is why free is cheapest at every difficulty, even hard ($1.15).
Why it is safe: it never collapses for language reasons. Every mandated arm has tasks where the mandate itself is the failure: every compiled arm scored ~4% on quickjs, Java scored ~0% on gron, Ruby scored 0% on zip-password-finder. Free choice dodges that whole failure class by switching languages, and collects partial credit instead: 63% on quickjs, 74% on gron, 76% on zip-password-finder.
But safe is not the same as best. Free wins on average pass rate, which rewards broad partial credit; it does not win on finishing tasks outright. Score instead by near-complete solves (the fraction of tasks that passed at least 75% of their tests) and free drops to 5th (13.5%), behind rust (16.7%), python, go, and ts. The gap is sharpest on the easy tercile, where fully solving a task is actually achievable: rust converts 50% of those tasks to a near-complete solve against free’s 38%. Rust nails the easy tasks it gets; free choice always gets something but finishes fewer of them.
So here’s what I would recommend:
If you know your tasks are easy CLIs, mandate Rust: it completes meaningfully more of them.
If you do not have a good opinion, or the workload is mixed, let the agent choose the language for you by telling it your requirements.
And the ceiling on better picking is lower than it looks: an oracle always picking the ideal language per task would score 59.3, about 7 points above free choice, and even that overstates the headroom, because taking the per-task max over eight noisy single runs banks run-to-run luck along with genuine language fit. A human mandating languages has to beat free choice without that hindsight.
Giving your agent free choice is the safe default: not the highest quality you can reach, but the most you can get without knowing much about the task, at the lowest cost.
Caveats
Per-task scores carry agent run-variance. Re-running the same agent on the same task can produce a different submission. The per-task figures here are one sample each, so small per-arm wiggles (a point or two) are noise; only the larger, consistent gaps should be read. Repeated runs would reduce the noise, but this eval is extremely expensive as-is and I can’t afford to scale it up much further.
Difficulty level is defined by the arms under study. “Hard” means “this panel of arms scored low,” which is endogenous: the bins come from the pooled mean of all nine arms, so each arm has a small hand in defining its own bins. As a robustness check, I recomputed the per-arm numbers under a leave-one-out difficulty (each arm binned by the other arms’ scores only) and the conclusions hold: Rust still leads the easy tercile, TypeScript still beats JavaScript on the hard tercile by about 4 points, and C is still last on both ends. As a second check, ProgramBench also ships an exogenous easy/medium/hard label (it exists for 161 of the 192 tasks), and the cross-arm mean score rises monotonically with it (official easy 64.5, medium 56.1, hard 35.1), so the difficulty axis is reasonably trustworthy.
Dig in yourself
The data is published in https://github.com/kunchenguid/programbench-bench/tree/main/blog/best-programming-languages-for-agents under data/, and every quote here is verbatim from a real trajectory. data/per-task.csv has the per-task pass rate, cost, and chosen language for all nine arms, and data/submissions/ has the code gpt-5.5 actually wrote for every task in every language: the same tool, reimplemented nine ways.
The charts and headline numbers are recomputable from that CSV; the native-language table additionally uses each task’s original-language label from ProgramBench’s task metadata, and the turn/build-cycle details come from the full transcripts. DATA.md documents the columns and the steps. n = 192 tasks per arm, nine arms, one model.
(The raw per-test eval JSON and full transcripts are too large to ship in the repo; they are available on request.)
Thank you.
Interesting article